Search Engine
Java
Software Development
Data Structures
Multi-threading
GitHub
Summary
This project was created for my Software Development class at the University of San Francisco.
This project was created in several steps over the course of the semester with each step expanding on the functionality of the last. The final result is a search engine programmed in Java that can accept a local file or url as input, build a dataset based on the input, and return search results. The project can be used from the command line or through a user interface created using embedded Jetty and Java servlets.
The search engine sources its data from local files or an input url. When using local files, the engine will parse through text files starting from the source directory to build its dataset. If the input is a url, the search engine uses a custom web crawler to parse through the url and any links on the page. By default the web crawler will only parse the input page but can be set to parse through additional links from the source url for a larger dataset.
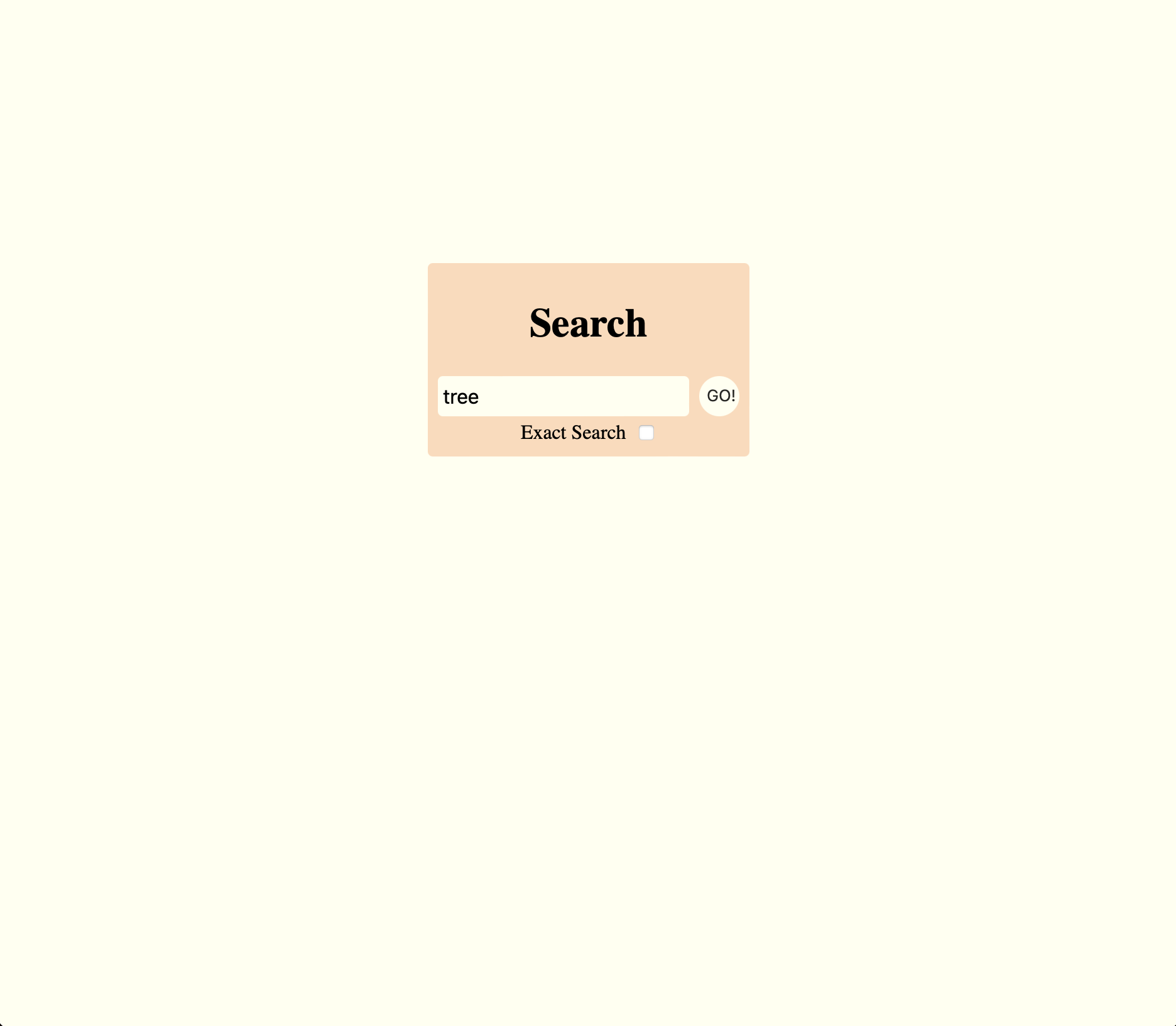
The images above show the search and results pages for the search engine user interface.
Part 1: Inverted Index
The first step of the project was to create the data structure needed to store words and their references. I created an inverted index to store a dictionary of words each pointing to a list of objects containing the file where the word was used and its position in the file. This system allows for a quick lookup of all places where the word has been found.
Part 2: Partial Search
The second step of the project was to utilize the inverted index from Part 1 to create partial and exact search algorithms.
The search algorithm can take multiple arguments and will return the most relevant sources. How relevant a source is is determined by how many times the searched words appear in the source divided the total amount of words. This system prioritizes sources where the words are used frequently and deprioritizes sources where the words are only used as a small fraction of the whole.
Part 3: Multi-threading
The third step of the project was to extend the functionality of the inverted index and search algorithms to work with multi-threading. When multi-threading is enabled, a new thread-safe inverted index is used instead of the default version. The thread-safe version is created with a custom read/write lock class to prevent errors caused by multiple workers editing the data structure at once. The main driver utilizes a work queue to read multiple source files at once. The default behavior of the project is to search using the single-threaded version. Multi-threading needs to be enabled when the program is started.
Part 4a: Web Crawler
Until now, data for the inverted index and searching was sourced from text files stored locally on the computer. The fourth step of the project was to source data for the search engine from the web using a web crawler. The program still maintains all previous functionality but can now accept a url as the source instead of a directory. When started from a url, the driver uses the work queue to assign all work for requesting and parsing any url to a single worker, with multiple workers running in parallel. If any links are found on the page, they will be added to the queue until a worker is assigned. The crawler can accept a limit to how many pages it will crawl before stopping itself (to prevent it from crawling forever) otherwise it will default to only using the source url.
Part 4b: Search Engine
The final part of the project was creating a frontend for users to interact with the search engine. For this I used embedded Jetty and servlets to create a web server in Java that sends an HTML response. When running the program, a web server is created with routes for home and results pages. The search page will search for anything entered into the uri parameters and display the results as links on the page.